映像から世界を構築する
DVF SLAM
DVF SLAMとは?
DVF(Deep Visual Fast) SLAMは深層学習を用いた弊社独自のSLAM技術です。 この手法では単眼・ステレオの両画像に対して高速で高精度な自己位置推定と密なマップの生成を行います。
DVF SLAMの特徴
DVF SLAMには様々な新機軸のアイデアが使われており、既存のSLAM技術が抱えている多くの問題を解決することが出来ました。
その特徴としては- 単眼画像での高精度なSLAM
- リアルタイムに再構成可能な軽さ
- 誘拐(kid napping )に対する頑強性
- 単眼・ステレオ両画像形式に対応可能
DVF SLAMのこれらの特徴は以下のような技術によって実現されています。
- ニューラルネットによって抽出された特徴量空間(Code Manifold)上での最適化
- 同じくニューラルネットによって抽出されたキーポイント(Learned keypoint)を用いた対応点計算と検索アルゴリズム
- 複数の目的に対し単一のニューラルネットのみを使用
ニューラルネットワークのアーキテクチャ
DVF SLAMで用いられるニューラルネットは画像入力に対し、画像、深度、キーポイント(マップ)を出力とする構造をしています。
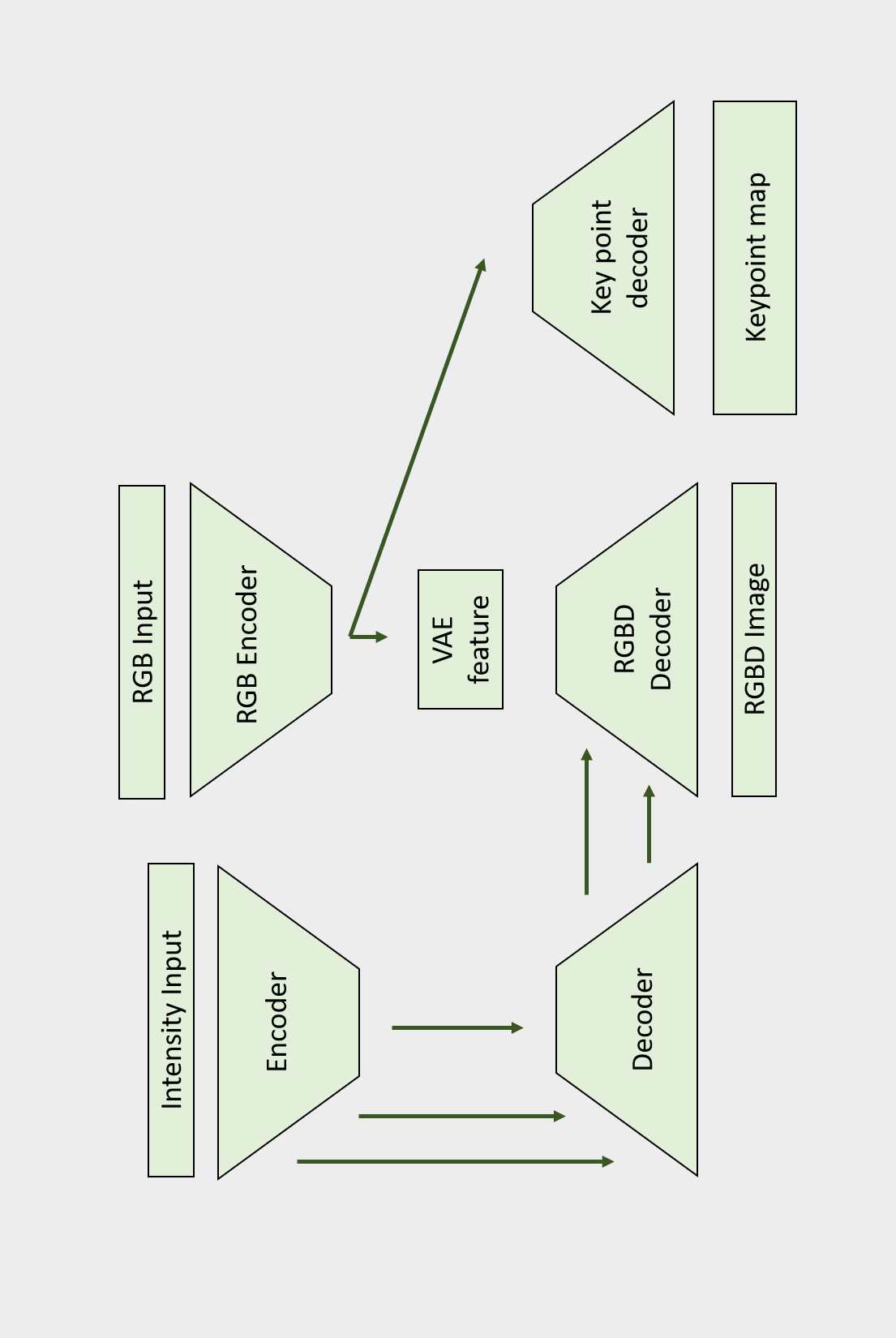
1列目のCNNはRGB画像を入力としてキーポイントの特徴量マップ\(K_{ijl}\)を出力します。
特徴量マップは同時にその地点における画像の顕著性(Saliency)も表していると考えることができます。画素\(i,j\)の各チャンネル\(l\)における最大値
\[ K^{*}_{ij} = \underset{l}{\max} K_{ijl} \]
に対して、一定の閾値を設けることで特徴点を検出することが出来、それに対応する\(K_{ijl}\)がその点の記述子となります。
このネットワークの学習は「Homographic Adaptation」と呼ばれる自己教師あり学習の手法で行うため、ラベル付けのような手間のかかる作業は必要ありません。
2列目、3列目のニューラルネットは途中で融合しており、RGB画像から深度を含めたRGBD画像を出力します。
2列目のCNNはVAEのような構造をしており、それによって特徴量空間はなめらかな表現空間を実現することが期待できます。
3列目はU-Net likeなスキップ接続のあるFCNで、これはVAEによってぼけてしまった部分を補助する役割を果たします。
姿勢グラフの最適化
2列目のCNN(VAE)によって抽出される特徴量は壁や床など、空間の持つ幾何学的な性質を表していると考えられます。 この低次元に圧縮された符号多様体(Code Manifold)上で最適化を行うことにより効率的で高精度な再構成が可能になります。 このアイデアはBloeschらのCodeSLAMで初めて用いられたものであり、DVF SLAMにおいても根幹をなすものとなっています。
姿勢グラフの推定は3つの損失関数- 画素の視差
- キーポイントの視差
- 幾何学的ずれ
各地点の姿勢は6自由度の変換行列\(T\)
\[ T \in SE(3) = SO(3) \ltimes \R^3 \]
で与えられ、例えば近い時刻にとられた画像\(i\)と\(j\)の間の画素同士の対応関係はワープ関数\(w\)を使って
\[ w_{ji}(x) = \pi(T_{ji}\pi^{-1}(I_{i}(x), D_{i}(c_{i},x))) \]
で与えられます。
ここで\(c_{i}\)は画像\(i\)に対応する特徴量であり、\(D_{i}(c_{i})\)はデコーダによって計算された深度、 \(\pi, \pi^{-1}\)は射影と逆射影関数を意味しています。
ワープ関数を用いると画素の視差に対する視差の損失は
\[ L_{pe} = \sum_{x\in\Omega_{i}}\|I_{i}(x)-I_{j}(w_{ji}(x))\| \]
と与えられます。
キーポイントの視差や幾何学的なずれについても同様の損失を与えることが出来ます。
このように損失関数は各フレームにおける姿勢\(T\)と特徴量\(c\)に依存しているため、 それぞれに対して最適化計算を行うことで姿勢と同時に対応する3次元地図を得ることが出来ます。
ループ検出と誘拐への対応
ループ検出と誘拐問題への対応は基本的には同じ画像検索に基づく手法によって行うことが出来ます。
ループ検出は現在見ている画像が過去に見た画像に似ているかどうかを調べることで行われます。
DVF SLAMではキーポイント特徴量を抽出しているので、古典的なBag of Visual Wordsモデルによって高精度・軽計算量で再訪を検出できます。
誘拐が発生した場合には、同様に画像検索を行い、データベース内に存在しないことが判明したら新たに地図の作成を開始し、既知の場所まで戻ってくることが出来たらループ検出と同様のアルゴリズムによって2つの地図を結合します。
このように、DVF SLAMでは1つのフレームワークによって多くのタスクを実現しており、その効率性によってリアルタイムな処理が可能になっています。